

El uso de datos está presente en casi todas las actividades o tareas de cualquier organización o compañía y se ha convertido en el gran recurso o activo en todos los ámbitos de la vida. Cada decisión a nivel operativo, táctico y estratégico se basa en grandes volúmenes de datos que son procesados y analizados desde diversas fuentes y con usos muy variados.

La explosión de datos es imparable y todos estamos ya familiarizados con el concepto Big Data, el cual ha venido acompañado de cientos de tecnologías, herramientas o procesos que han permitido, entre otras cosas, la organización, administración o manipulación de enormes repositorios para ponerlos al servicio del negocio.
En esta línea, algunos de los beneficios que se pueden obtener al organizar y gestionar los datos también están claros.Comprender mejor las necesidades de los clientes, mejorar la calidad de los servicios ofrecidos, mejorar la planificación y la previsión o incluso predecir y prevenir riesgos. Estos son algunos de esos beneficios que, a su vez, llevan implícitos la propia evolución que estamos viviendo de disciplinas orientadas a la Inteligencia Artificial.
Sin embargo, para alcanzarlos y generar valor a partir de las soluciones basadas en Big Data y AI, es imprescindible tener en cuenta el significado y calidad de los datos, así como comprender su contexto de uso.
Nuevos retos en la era del Big Data
Hubo un tiempo que las organizaciones y grandes compañías utilizaban los datos generados única y exclusivamente a partir de sus propios entornos y sistemas. Los productores de datos eran, en su mayor parte, los mismos que los consumían y su calidad no representaba un problema.
Descubrir información que fuera relevante, y que permitiera tomar decisiones a partir de una gran cantidad y variedad de datos, puede que llevara tiempo pero no dejaba de ser una tarea más a conseguir para lograr la ansiada ventaja competitiva.
Ahora, los datos recogidos y analizados, provienen de una mayor diversidad de fuentes con tipologías muy variadas y estructuras más complejas. A su vez, el número de productores y consumidores de datos ha crecido y la diferenciación entre estos y otros perfiles de usuario puede ser mayor. En consecuencia, determinar la calidad en orden a la necesidad de cada uno de ellos implica más esfuerzo y recursos.
Añadimos más variables a este planteamiento. ¿Cuáles son las características que definen la calidad para un usuario determinado?. Si un data scientist está trabajando sobre un modelo predictivo con los datos de los clientes, puede que la precisión le parezca más importante que el volumen o la máxima actualidad de esos datos. Si por el contrario, es el departamento comercial el que está lanzando una oferta y requiere de esos mismos datos, no será tan importante la precisión o exactitud como la accesibilidad o la pertinencia de los mismos.
Para el departamento de contabilidad, la fecha de nacimiento del cliente no es un campo obligatorio. Ante su ausencia, ellos consideran que los datos de ese cliente no son de mala calidad. Pero marketing considera ese campo clave, así que dicho departamento puede valorar que los datos de contabilidad no tienen calidad.
Aun más, el trabajo de un equipo médico puede verse seriamente comprometido si los datos que utiliza son imprecisos, inaccesibles, irrelevante o incompletos.
Por tanto, la calidad de los datos puede ser definida por su valor de negocio, por objetivos concretos o por las prioridades que marque la propia organización. Pero en todo este planteamiento se demuestra también que los usuarios son un componente clave en la definición que se haga de esa calidad.
Alcanzar una calidad de datos óptima, hacerlo en un plazo de tiempo razonable y con un volumen de datos en continuo crecimiento se convierte en un desafío difícil de afrontar.
Ahora bien, definir y mejorar de forma continua la calidad de los datos tampoco es un objetivo que pueda quedar aislado ni relegado a un grupo de personas, departamento/s o tecnología.
Como señala Gartner, este desafío afecta a organizaciones de todos los tamaños y puede destruir el valor del negocio o producir perdidas pocas veces valoradas en los resultados de las compañías.
Data Quality
La calidad de los datos o Data Quality es un area de trabajo e investigación que comenzó en la década de los 90, con el rápido crecimiento de las tecnologías de la información y la comunicación.
En la década anterior la preocupación había estado centrada en la calidad misma de los productos y en el grado en el que sus características y funcionalidades cumplían con los requisitos. Fue una época en la que se consolidó la definición ampliamente aceptada de calidad como conformidad con los requisitos.
El trabajo de Joseph M. Juran da buena cuenta de esa búsqueda constante de la calidad y satisfacción del producto e incorpora una nueva y sencilla definición: adecuación al uso (fitness for use). Esta definición ha sido ampliamente utilizada en la literatura sobre Data Quality y constituye un buen punto de partida para evaluar hasta qué punto los datos sirven para los fines o necesidades de los usuarios.
El grupo Total Data Quality Management del MIT University, liderados por el profesor Richard Y. Wang, dio continuidad al trabajo de Juran y llegó a definir un conjunto de atributos o dimensiones para medir y gestionar la calidad de los datos. Categorías útiles cuya evaluación puede ser automatizada para valorar la idoneidad y adecuación de los datos en orden a objetivos de negocio o necesidades de los usuarios.
Dimensiones de la calidad del dato
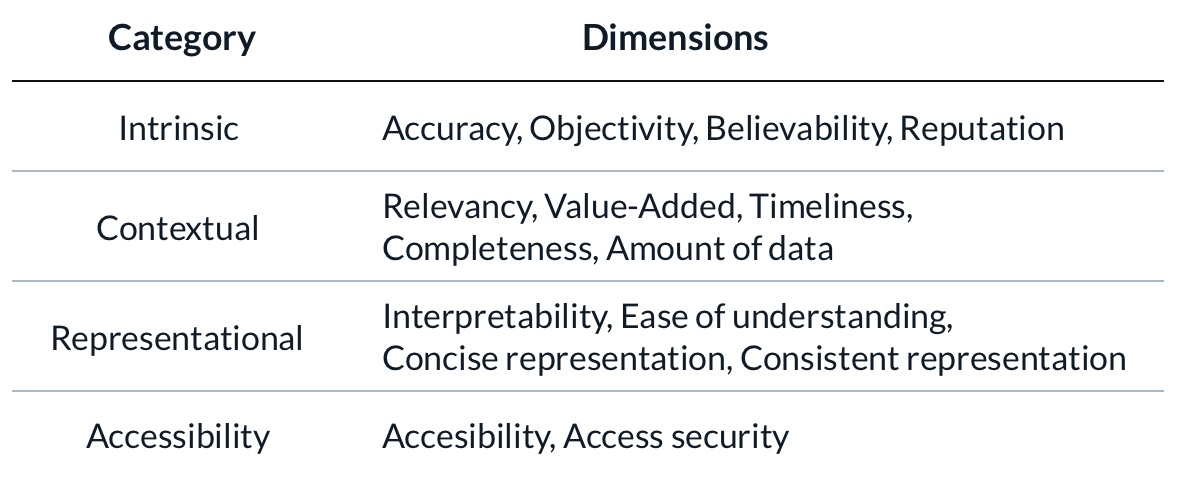
Wang y Strong (1996) en su artículo Beyond Accuracy: What Data Quality Means to Data Consumers (PDF) proponen una división en 4 categorías con un total de 15 dimensiones:
–Intrínseca: Los valores de los datos se ajustan a los valores reales o actuales.
Dimensiones: Credibilidad, exactitud, objetividad, reputación.
–Contextual: Los datos son aplicables (pertinentes) a la tarea del usuario del dato.
Dimensiones: Valor añadido, relevancia, pertinencia temporal, completitud, cantidad de datos.
–Representativa: Los datos son presentados de forma inteligible y clara.
Dimensiones: Interpretabilidad, facil de comprender, consistencia representacional, representación concisa.
–Accesibilidad: Los datos están disponibles o es posible acceder a ellos.
Dimensiones: Accesibilidad, seguridad de acceso.
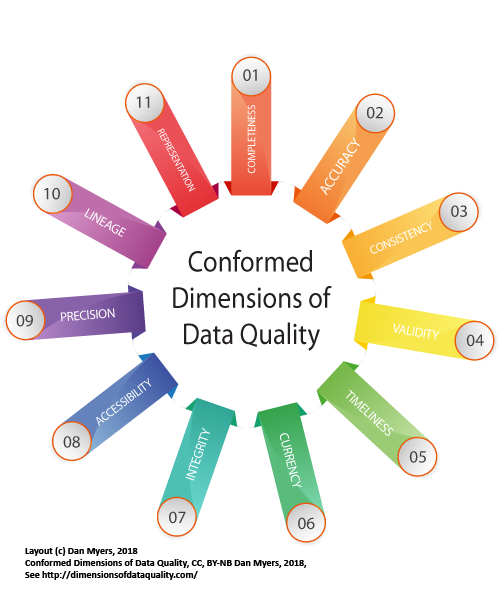
Estudios posteriores han ido modificando esta clasificación y el listado de dimensiones que engloba. En 2013 Dan Myers hizo un estudio comparativo y propuso una nueva lista (Conformed Dimensions of Data Quality) evitando conflictos terminológicos y buscando la comprensión y la estandarización.
Algunas organizaciones como la Data Administration Management Association (DAMA) o Data Warehousing Institute (TDWI) han aportado sus propias clasificaciones y definiciones, llegando a un total de 6 dimensiones fundamentales para la gestión de la calidad del dato (PDF). Serían las siguientes:
- Exactitud (Accuracy): Se mide el grado en el que los datos representan correctamente el objeto del mundo real o un evento que se describe.
Ejemplo: La dirección de envío de pedidos a un cliente en la base de datos de clientes es la dirección real.
- Completitud (Completeness): El grado en el que el dato tiene el valor esperado y cumple con los requerimientos marcados. Si un dato es opcional no debe considerarse para lograr el 100% de completitud.
Ejemplo: Podemos establecer que los clientes tendrán sus datos completos si hemos registrado su nombre, primer apellido, segundo apellido, número de identificación, e-mail, dirección, código postal, ciudad y país. El segundo nombre será opcional.
- Consistencia (Consistency): Mide si los datos están libres de contradicción y tienen coherencia lógica, de formato o temporal.
Ejemplo: Para un cliente determinado tenemos ventas registradas pero no nos consta ninguna orden de pedido.
- Pertinencia temporal (Timeliness): Mide el grado en que los datos están disponibles cuando se requieren.
Ejemplo: Para la asignación de habitaciones en un hotel, la recepción debe contar con el número actualizado de habitaciones disponibles en el momento de registrar la llegada del cliente.
- Unicidad (Uniqueness): Cada dato es único. Con esta dimensión se busca corregir la duplicidad inesperada en nuestros dataset.
Ejemplo: En nuestra base de datos podemos tener dos clientes que se registraron como «Fran García» y «Francisco Juan García», siendo la misma persona pero sólo el último contiene todos los datos completos.
- Validez (Validity): Medir si un valor se ajusta a una regla de negocio o a un estándar preestablecido en cuanto a formato, tipo de dato, valores posibles o rangos especificados.
Ejemplo: En el seguimiento de entrega de un pedido, la última actualización es posterior a la hora actual. Dan Myers expone este caso en su blog explicando que si existiera una regla de negocio que indique que las actualizaciones no pueden producirse en una fecha y hora superior a la actual del sistema, este problema no se hubiera producido.
Todas estas dimensiones son atributos que no representan la calidad real de los datos. Una compañía con buena calidad de los datos no es necesario que cumpla, por ejemplo, con el 100% de completitud o de unicidad de los datos.
La calidad viene dada por cómo alineamos los requisitos de datos de negocio con los niveles de cada una de estas dimensiones.
Incluso es posible que los datos que estaban completos para un proceso dado, en un proceso futuro pueden estar incompletos o requieran de un nuevo planteamiento desde negocio.
Los procesos de negocio y los casos de uso que se vayan definiendo exigen una mejora continua de la calidad.